Why “Making a Chatbot” and “Creating an AI Assistant” Are Not the Same Thing
AI Development
Why “Making a Chatbot” and “Creating an AI Assistant” Are Not the Same Thing
Alexander Khodorkovsky
•
November 3, 2025
•
8
min read
Most organizations have deployed chatbots. Still fewer have launched AI assistants that are able to reason over context, pull live data, or coordinate across systems. And as LLMs and RAG pipelines move beyond experimental (and relatively small) to production scale, the distinction between a chatbot and an assistant is not merely one of raw capability; it’s architectural. We’ll break that down, from system design to integration points and decision points for enterprise adoption.
Chatbot vs. AI Assistant: Key Differences
Both systems might employ conversational interfaces, but how they’re put together (and their worth to the business) are worlds apart.
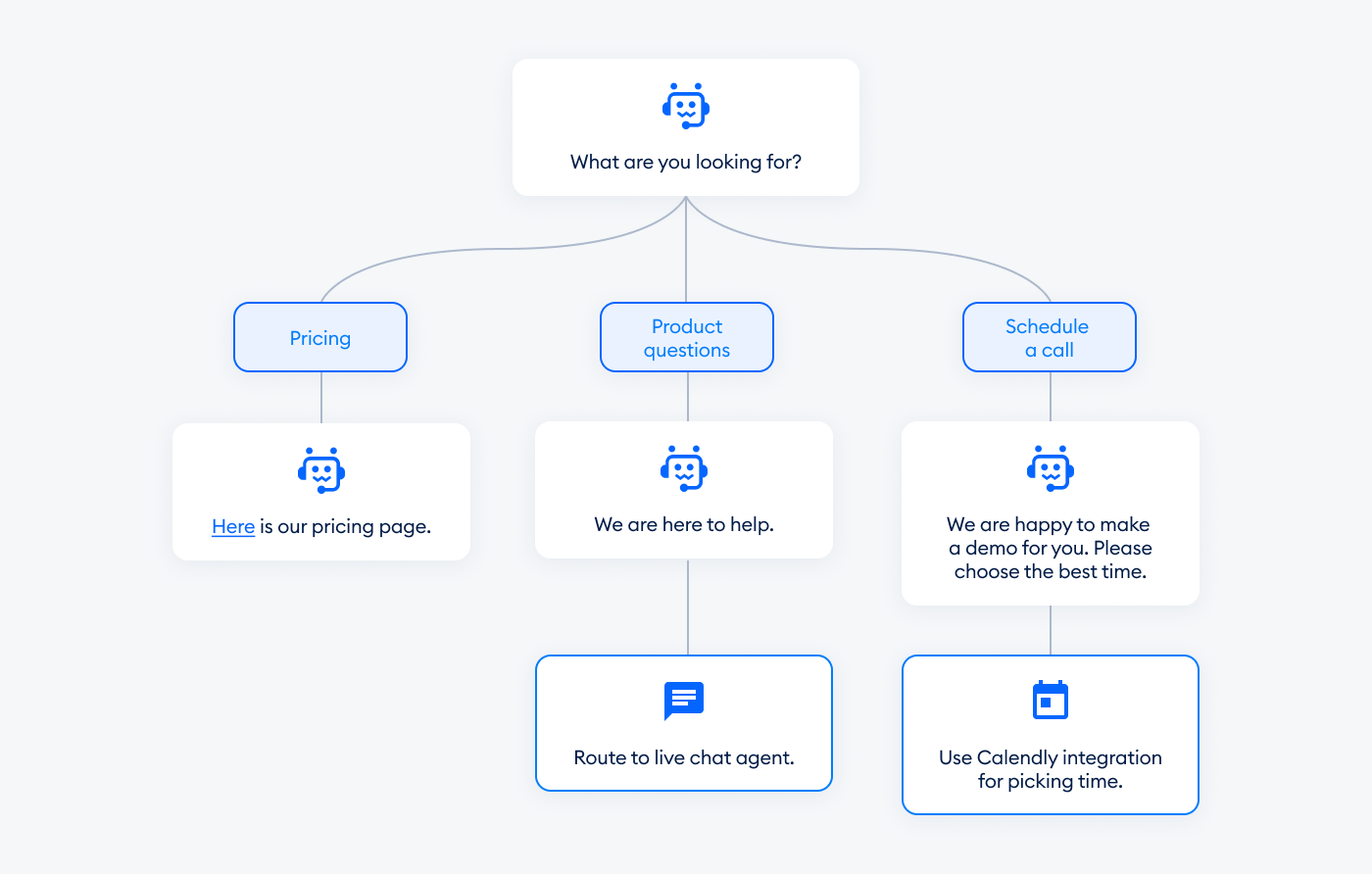
Chatbots run on deterministic logic. They respond with rule-based flows, intent classification, and pattern matching. Each move is programmed, and entering anything other than the requested input will certainly decrease accuracy. These systems are typically based on finite state machines or decision trees. They work well only for discreet functions, like routing a support ticket or answering a pricing question. By design, though, it can be only so flexible. And they can respond only in one box that you’ve devised in the development, so to speak.
Source: https://www.tidio.com/blog/ai-chatbot/
AI assistants function differently. They understand complex language with LLMs. Assistants respond to dynamic input, even if that's presented in an unfamiliar form. Rather than choosing among a fixed list of actions, they generate outputs token by token. They can now integrate with fresh knowledge extracted from private databases, document stores, or API responses when RAG is used. That means an assistant can respond to more complex questions using the live context, say, by pulling a specification from a knowledge base or summarizing a contract clause, without retraining the model.
What makes them different is how they act under pressure. When the flow is broken, the chatbot breaks. An AI assistant recalculates. That has the assistant suited for workflows where language is varied, goals are less predictable, and integration with enterprise systems is key.
Architecture: Decision Tree vs. LLM + RAG
Typical chatbots are built on deterministic modules programmed to complete finite repetitive tasks. Their architecture usually includes:
Intent Classifier: Uses keyword matching or shallow machine learning models (e.g., logistic regression, SVMs) to map user inputs to pre-defined intents.
Entity Recognition/Slot Filling: Finds variables (dates, names) in utterances to fill templates or trigger actions.
Dialogue Manager: Controls the flow of conversation by decision trees or finite-state machines. Each node corresponds to a rule or reaction that is hardcoded.
Response Templates: Fixed text outputs or JSON objects selected based on the conversation state.
This approach is effective for structured workflows (e.g., support ticket routing and/or static FAQs), where the outcomes are tightly controlled. However, the model degrades when:
The intents grow rapidly.
The inputs get shuffled up syntactically or semantically.
Cross-intent dependencies or long-range context are needed.
Modern AI assistants implement a fundamentally different stack. Core components include:
Large Language Model (LLM): For natural language understanding and generation with transformer-based architectures (e.g., GPT, Claude, Gemini). Operates without rigid state management.
Embedding + Vector Search Layer: Transforms user query and documents to high-dimensional embeddings. Leverages similarity search (e.g., FAISS, Weaviate, Qdrant) to look up relevant context pieces.
Retrieval-Augmented Generation (RAG): Joins LLMs with retrieved documents or API results, injecting external information into the prompt to ground responses. Usually, retrieval and reranking are gated by a retriever-ranker pipeline.
Tool Use and Agent Loop: Supports actions such as calling APIs, querying databases, or executing code. An agent loop architecture enables multi-step reasoning (e.g., using ReAct or Plan-and-Execute patterns) where the assistant decides which tool to call and proceeds iteratively.
Context Management Layer: Maintains in-session memory via conversational history, and optionally includes vector-based long-term memory for persistent personalization or task continuity.
This architecture supports:
Unbounded input phrasing;
Document-grounded QA without model retraining;
Tool integration with conditional logic;
Multi-step reasoning where the assistant handles ambiguity and decomposes tasks into actions.
In short, chatbots operate within a branching tree. AI assistants operate in a context loop. The former is ideal for predictable flows. The latter is engineered to retrieve and act, even when the task isn’t clearly defined at the outset.
Case Studies: When a Chatbot Still Works, and When You Need AI
Transformers aren’t required on all systems. In low-variance environments, upfront rule-based chatbots can still offer decent ROI, particularly when workflows are extremely scoped and language input is shallow.
Consider Delta Airlines’ flight booking assistant, for instance. Virtually all users go through the same intent flow: select origin, destination, and date. A chatbot with a rule-based system and slot filling of sequential FSM can accomplish the flow with a near 100% success rate. There’s very little ambiguity, no reliance on long-range context, and hard business rules. Placing an LLM here not only adds to cost; it creates a burden of variability where consistency is the objective.
Likewise, banking customer service bots can be designed to be very specific. At the start, a user types, “What’s the daily transfer limit?” The chatbot performs a pattern match or an intent classifier and responds with the templated response. When the policy changes, the content manager modifies a static field with no retraining process, no retrieval stack, and no built-in knowledge base. It keeps the system simple to maintain and test, which is important in financial compliance.
But now let’s consider a different use case: an assistant in legal ops at a tech company has been assigned to read NDAs. A teammate inquires, “What 2023 NDAs can we train external models on internal data on?” This necessitates multihop reasoning: to retrieve the documents, comprehend the legal language of the contract, match clauses that mention AI training, and summarize the permissions. A rule-based bot simply does not have the capacity to generalize across variable wordings or dual existing documents. An LLM-backed assistant, retrieval-augmented generation, and clause-level summarization can finish that job in seconds, performed on your own document trove.
Another example: IT support in a large enterprise. A user types, “I just got a 403 from the Jenkins staging pipeline when triggering a deployment.” Who can fix this?” The assistant has to be aware of internal vocabulary (Jenkins, staging, deployment), look up access policies across systems, and perhaps even call an internal API to check group attributes. It could draw in even recent error logs via tool use. No flowchart would have predicted this structure, but an AI assistant can unpack the query, look up the relevant sources, and answer with specific, context-grounded actions.
Advantages of an AI Assistant: Context, Memory, Integrations
Context Windows & Memory Capabilities
Contemporary LLMs also stretch the limits of how much “working memory” they hold over just one turn. Today's models typically support context windows containing 100,000 to 200,000 tokens; a few experimental and research‐grade editions may offer window sizes of 1 million tokens or more.
Why it matters: from a greater context, AI assistants are able to consume long documents (technical manuals, draft policies) or remember extensive conversation histories without cutting off and discarding earlier sections. For instance, the research indicates that missing context errors drop precipitously as the context window grows, which means you don’t have to do any manual chunking or fancy sliding-window logic.
Memory features are also becoming increasingly common in commercial systems. A recent rollout by Anthropic made memory available for Team and Enterprise customers, enabling the assistant to retain project details, user preferences, names, and other recurring context. This helps to enhance user satisfaction and continuity within multi-session workflows.
RAG architectures provide knowledge for assistants in the form of external sources (e.g., document stores, databases, or live data streams), ensuring that responses are up-to-date and anchored. A number of recent studies support the impact of RAG:
Another work, “DRAGON: Efficient Distributed RAG …” shows that when the workload is split between device and cloud, we are able to achieve up to 1.9× better latency performance of centralized RAG systems while maintaining the same output quality.
Additionally, benchmarks and product reports indicate RAG reduces hallucinations when compared to LLMs operating without external retrieval mechanisms.
Integrations & Tooling
AI assistants integrate with systems and tools in ways chatbots rarely do:
Tool / API Invocation: Assistants can call external APIs, query proprietary databases, pull live metrics. Used in monitoring dashboards, custom analytics, or retrieving internal customer data. This enables end‑to‑end workflows instead of just performing scripted question/answer.
Agent Loops: Architectures such as ReAct, Plan‑and‑Execute, etc., enable assistants to decompose the complex tasks. Like fetching some relevant data, processing it, and deciding next steps on the fly. Valuable in process automation, legal reasoning, and product engineering.
Memory + Retrieval + UI Integration: A hybrid memory strategy combining summary memories + recent turns (sliding window) is appearing in production settings (e.g. in Azure OpenAI + LangChain setups). Teams use the summary to capture long‐term context (user goals, project scope), then feed in the most recent turns to preserve tone and immediate context. Costs (in tokens, compute, latency) are managed via budgeted token windows (~8K‑16K tokens in many cases) and choosing which retrieval results to surface.
Limitations: Cost, Latency, Data
AI assistants provide architectural benefits, but they also introduce complexity and therefore real operational trade-offs that impact deployment, scalability, and governance.
Compute and Latency Overhead
Large context windows come at a cost. Most transformer-based LLMs operate with attention mechanisms that scale quadratically with input length. Doubling the token window can more than double the time. In terms of latency numbers, a jump from 16K to 100K tokens can multiply the latency by at least 3–5×, and that would actually push inference workloads out of any real-time bounds, especially on-prem or hybrid setups.
In retrieval-augmented generation (RAG) pipelines, this latency stacks: for each user-issued query, a vector similarity search is executed, and a prompt and LLMs are both built. If you are pulling in documents from multiple sources or re-sorting and re-ranking during the interaction, response time can get even worse, often to several seconds per turn. In time-critical workflows, that delay might be unacceptable.
Memory Risks and Governance Gaps
If assistants remember users, sessions, or the organizational context of them, then the system has to deal with how to version this data, its user-specific access control, and long-term retention policies. Without strong governance, memory is a liability. It leaks sensitive data across sessions or holds on to outmoded assumptions.
Vendors like Anthropic and OpenAI now allow users to examine or erase memory objects. But for enterprise use cases, auditability, consent logging, and SOC2 compliance aren’t just optional. Enterprises must embed memory within broader data governance programs, complete with observability, rollback, and TTL logic for stale context.
RAG Pipelines Depend on Retrieval Quality
A RAG stack is nothing without its retrieval layer. Bad document curation, obsolete data, or weak embedding techniques can yield irrelevant results: nonsensical answers or made-up facts. With a good vector search, though, one may still need ranking and chunking strategies to minimize the drift between what the assistant retrieves and what the user really meant.
To retain the high retrieval precision, teams must manage:
Index health (e.g., vector database size, latency, quality of nearest-neighbor matches).
Tool Use Expands Surface Area for Failures
Agent loops and dynamic tool use introduce power—and fragility. Assistants who chain API calls or query internal systems must handle lots of processes (from tool availability to response schemas). One crappy API response or malformed intermediary step can mangle the whole train of thought.
For instance, if a sales assistant queries the incorrect revenue system and receives data from a deprecated environment, the ultimate report will likely have inaccurate metrics. It can also be difficult to debug these if there isn't good observability and retry logic.
Toolchains also require isolation policies, rate limiting, and audit logging. And in heavily regulated industries, this is an architectural requirement, not a best practice.
How to Choose: Decision Matrix for Business
Question
If YES → Consider:
Explanation
Do users phrase requests in open-ended or non-standard ways?
Do answers require pulling from internal documents, KBs, or APIs?
AI Assistant with RAG
Retrieval pipelines and grounding mechanisms are required for accuracy.
Is low latency critical (under 500ms per turn)?
Chatbot
LLMs with RAG often exceed 2–3s roundtrip latency without aggressive optimization.
Does the workflow involve deterministic flows or strict business rules?
Chatbot
Easier to control and test; useful in regulated environments.
Are multiple backend tools involved (e.g., CRM + BI + ticketing)?
AI Assistant with Tool Use
Agent loop architectures can coordinate cross-system actions dynamically.
Is memory or session persistence important across conversations?
AI Assistant with Memory Layer
LLM-based assistants can retain identity, preferences, and long-term context.
Is budget predictability more important than dynamic flexibility?
Chatbot
Static flows avoid unpredictable token consumption and reduce infra costs.
If your current chatbot has brushed up against architectural constraints: resisting to unstructured questions, being unable to plug into back-end tools, or requiring hourly manual input; then maybe it’s time for you to consider a full AI assistant. But going from flows to functions and scripted replies to retrieval-backed reasoning isn’t a plug-and-play upgrade. It’s a system redesign.
We work with businesses to scope, architect, and deploy AI assistants that reflect actual workflows, compliance requirements, and integration environments. Whether you're enhancing your existing chatbot or creating a fully autonomous agent layer, our team can help you through the choices that count.
Thinking about whether to turn your chatbot into a full-blown AI assistant? Talk to us! We can help you scope the right solution and get it running in your system.
Oops! Something went wrong while submitting the form.
Author Name
Comment Time
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius enim in eros elementum tristique. Duis cursus, mi quis viverra ornare, eros dolor interdum nulla, ut commodo diam libero vitae erat. Aenean faucibus nibh et justo cursus id rutrum lorem imperdiet. Nunc ut sem vitae risus tristique posuere. uis cursus, mi quis viverra ornare, eros dolor interdum nulla, ut commodo diam libero vitae erat. Aenean faucibus nibh et justo cursus id rutrum lorem imperdiet. Nunc ut sem vitae risus tristique posuere.
Oops! Something went wrong while submitting the form.
Author Name
Comment Time
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius enim in eros elementum tristique. Duis cursus, mi quis viverra ornare, eros dolor interdum nulla, ut commodo diam libero vitae erat. Aenean faucibus nibh et justo cursus id rutrum lorem imperdiet. Nunc ut sem vitae risus tristique posuere. uis cursus, mi quis viverra ornare, eros dolor interdum nulla, ut commodo diam libero vitae erat. Aenean faucibus nibh et justo cursus id rutrum lorem imperdiet. Nunc ut sem vitae risus tristique posuere.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
Oops! Something went wrong while submitting the form.
Our Blog
Recent Publications
Explore our recent posts on gaming news and related topics. We delve into the latest trends, insights, and developments in the industry, offering valuable perspectives for gamers and industry professionals alike.
AI News Digest #3: The Biggest AI Developments of Q4 2025 & Early 2026
Stay ahead with AI News Digest #3: explore top AI developments from Q4 2025 to early 2026, including new model releases, agentic AI, EU AI Act updates, and real-world business adoption shaping the future of AI.
April 14, 2026
•
6
min read
AI Development
Hidden Value of AI: How to Leverage Knowledge Graphs and Personalization
Hidden value of AI lies in context. Discover how knowledge graphs and real-time personalization unify data, improve accuracy, and drive scalable growth, better decisions, and higher ROI across the enterprise.
April 2, 2026
•
10
min read
AI Development
The Future of AI in Cybersecurity: Opportunities and Threats
AI is transforming cybersecurity in 2025, driving both advanced threat detection and AI-powered attacks. Explore how businesses can leverage AI for defense, mitigate risks like deepfakes and polymorphic malware, and build an AI-first security strategy.









Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius enim in eros elementum tristique. Duis cursus, mi quis viverra ornare, eros dolor interdum nulla, ut commodo diam libero vitae erat. Aenean faucibus nibh et justo cursus id rutrum lorem imperdiet. Nunc ut sem vitae risus tristique posuere. uis cursus, mi quis viverra ornare, eros dolor interdum nulla, ut commodo diam libero vitae erat. Aenean faucibus nibh et justo cursus id rutrum lorem imperdiet. Nunc ut sem vitae risus tristique posuere.
Reply